Md Muhtasim Munif Fahim, M. Monimul Huq, M. Sabiruzzaman, Md. Rezaul Karim
The revised arXiv preprint is now on v2 and reflects the current BMC Public Health submission. In a four-round BDHS benchmark, validation-regime choice changed screening workload estimates more than architecture choice, making temporal splits and capacity-based metrics essential before programmatic use.
BMC Public Health · 2026 · submitted · arXiv:2602.03957
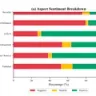
Bangladesh has reduced under-five mortality substantially, but preventable deaths remain unevenly distributed across households and divisions. Prediction models based on Demographic and Health Survey (DHS) data could help planners prioritise follow-up, referral, and resource allocation—but only if reported performance reflects future public-health use. We analysed four Bangladesh DHS rounds (2011, 2014, 2017, and 2022; 33,962 children; 1,290 under-five deaths), evaluating identical 26-feature pipelines and three model classes under four validation regimes: pooled random 80/20, matched-size pooled random, 2022-only random, and cross-survey temporal validation (train 2011+2014, validate/calibrate on 2017, test on 2022). A 32-unit ELU multilayer perceptron selected by genetic-algorithm neural architecture search was compared with XGBoost and logistic regression. Validation regime changed public-health interpretation more than model class: AUROC ranged from 0.669 under 2022-only random validation to 0.775 under pooled random validation, with a temporal estimate of 0.730. At the top-10% temporal screening threshold, the model identified 152 of 355 observed 2022 deaths (sensitivity 42.8%, PPV 13.2%, NNS 7.6). Across validation designs, the same model implied number-needed-to-screen values from 5.6 to 11.0—changing the expected follow-up workload substantially. Cross-round temporal validation gives planners a more defensible basis for estimating community-health-worker follow-up, referral demand, and budget scenarios than random-split AUROC alone.
High digital engagement makes students more vulnerable to infrastructure failures, not less. We call this the 'Dependency Divide', and targeted reliability improvements for heavy users yield 2× the return of blanket interventions.
While digital access has expanded rapidly in resource-constrained contexts, satisfaction with digital learning platforms varies significantly among students with seemingly equal connectivity. This study introduces the 'Dependency Divide', a novel framework proposing that highly engaged students become conditionally vulnerable to infrastructure failures, challenging assumptions that engagement uniformly benefits learners in post-access environments. Using a cross-sectional study of 396 university students in Bangladesh, we apply K-prototypes clustering, profile-specific Random Forest models with SHAP and ALE analysis, and formal interaction analysis with propensity score matching. Three profiles emerged: Casually Engaged (58%), Efficient Learners (35%), and Hyper-Engaged (7%). A significant interaction between educational device time and internet reliability (β = 0.033, p = 0.028) confirmed the Dependency Divide: engagement increased satisfaction only when infrastructure remained reliable. Policy simulations demonstrated targeted reliability improvements for high-dependency users yielded 2.06× greater returns than uniform interventions.
Width should grow 2.8× faster than depth in transformers, validated across 30 architectures up to 7B parameters. Past a critical depth, adding layers actively hurts, even though parameter count increases.
Neural scaling laws describe how language model loss decreases with parameters and data, but treat architecture as interchangeable. We propose architecture-conditioned scaling laws decomposing depth-width dependence, finding that optimal depth scales as D* ~ C^0.12 while optimal width scales as W* ~ C^0.34, meaning width should grow 2.8× faster than depth. We discover a critical depth phenomenon: beyond D_crit ~ W^0.44 (sublinear in W), adding layers increases loss despite adding parameters, the effect we call the Depth Delusion. Validated across 30 transformer architectures spanning 17M to 7B parameters (R² = 0.922), our central finding is that at 7B scale a 64-layer model (6.38B params) underperforms a 32-layer model (6.86B params) by 0.12 nats, despite being significantly deeper. This demonstrates that optimal depth-width tradeoffs persist at production scale.
The revised preprint maps all 17 SDGs across 114 countries and finds 84 supported directed linkages after false-discovery control. No single goal behaves as a stable universal accelerator, so portfolio policy should track time-lagged, evidence-backed linkages instead of rankings alone.
Governments with limited fiscal and administrative capacity need to know which Sustainable Development Goals (SDGs) propagate progress through the goal system and how quickly. We map the directed interdependence structure of all seventeen goals using a balanced panel of 114 countries observed annually from 2000 to 2024. The goal series are persistent, trending, and cross-sectionally dependent, so we apply two estimators matched to this regime: a Dumitrescu-Hurlin panel Granger non-causality test, run on first-differenced series, to recover the directed interaction network, and panel local projections with Driscoll-Kraay standard errors to measure the dynamic magnitude of 31 theory-derived indicator linkages. Of 272 directed goal pairs, 84 linkages survive false-discovery control (40 synergies, 44 trade-offs; network density 0.31). Synergies and trade-offs occur at comparable strength, so no single goal behaves as a universal accelerator, and the goal-level hierarchy itself is fragile. Driver-receiver rankings correlate weakly across lag orders and centrality metrics, and under a country bootstrap only two roles are distinguishable from zero: peace and strong institutions as the clearest net receiver, and poverty reduction as the most probable effect-size-weighted driver. The supported linkages are dynamic, accruing over four to five years: sanitation and poverty improvements are the strongest predictors of lower child mortality, and the education-child-health association is corroborated in independent World Development Indicators data across 183 countries. These results caution against rankings-based accelerator policy and support adaptive portfolios built on supported, time-lagged linkages monitored through constituent indicators.
Multilingual sentiment classification of government mobile banking app reviews (English + Bangla). Benchmarks several architectures for monitoring public service quality through NLP.
This study presents a multi-model approach for sentiment classification of user reviews of government mobile banking applications in Bangladesh, handling both English and Bangla language inputs. We benchmark several classification architectures on a curated review dataset and evaluate their performance across sentiment categories, with implications for public service improvement and digital governance monitoring.
239× fewer parameters than GraphCast at near-identical accuracy. Principled multi-objective NAS can find truly deployable models, and transfer learning adds ~5% accuracy gains when historical data is scarce.
2026 IEEE 2nd International Conference on Quantum Photonics, Artificial Intelligence & Networking (QPAIN) · 2026 · published · arXiv:2602.00240
Neural Architecture SearchWeather ForecastingEdge ComputingGreen AI
Abstract
We introduce Green-NAS, a multi-objective neural architecture search (NAS) framework designed for low-resource environments using weather forecasting as a case study. Adhering to Green AI principles, the framework explicitly minimizes computational energy costs and carbon footprints, prioritizing sustainable deployment over raw computational scale. The search simultaneously optimizes model accuracy and efficiency to find lightweight architectures with very few parameters. Our best-performing model, Green-NAS-A, achieved an RMSE of 0.0988 (within 1.4% of a manually tuned baseline) using only 153k parameters, 239 times fewer than globally deployed models such as GraphCast. Transfer learning improves forecasting accuracy by approximately 5.2% compared to training a new model per city when historical data is limited.
Saiful Islam, Md. Palash Bin Faruque, Tanjina Khan, Most. Shabrina Afroz, Tofayel Ahmed, Md Muhtasim Munif Fahim, Md. Kamruzzaman, Md. Mostafizur Rahman, Md. Abdul Khalek
Hybrid model (SVM+RF+XGBoost) predicts early childhood development in Bangladesh with 0.77 accuracy (cognitive) and 0.71 (social-emotional). SHAP reveals domain-specific drivers: books and education for cognition, caregiving and discipline for social-emotional outcomes, with urban-rural subgroup divergences informing targeted SDG 4.2 interventions.
2026 IEEE 2nd International Conference on Quantum Photonics, Artificial Intelligence & Networking (QPAIN) · 2026 · published
Machine LearningSHAPXGBoostEarly Childhood Development
Abstract
Early childhood cognitive and social-emotional development is crucial for shaping lifelong health, education, and productivity. However, many children in low- and middle-income countries don't achieve their growth potential. This study applies a hybrid machine learning framework with explainable artificial intelligence SHAP to predict early childhood cognitive and social-emotional development outcomes in Bangladesh and also identify the key contributing factors. Using nationally representative data from the Bangladesh Multiple Indicator Cluster Survey (MICS) 2019, a sample of 9,455 children aged 36–59 months was analyzed. Cognitive and social-emotional improvement were modeled as binary outcomes was described on the basis of individual classifiers (Support Vector Machine, Random Forest, XGBoost, and Logistic Regression) and a hybrid model that combined SVM, RF, and XGBoost. The model was measured using accuracy, precision, recall, F1-score, specificity, and ROC-AUC to evaluate the level of performance, and SHAP explainability was applied to enhance interpretability. Moreover, subgroup SHAP analysis was conducted to compare feature contributions for urban and rural children. The hybrid model achieved the best overall performance in both domains, with an accuracy of 0.77 and ROC-AUC of 0.79 for cognitive development, and an accuracy of 0.71 and ROC-AUC of 0.72 for social-emotional development. Access to children's books, the child's age, and signing up for early childhood education were the most important factors in cognitive growth. The social-emotional development was most strongly related with the contextual and caregiving factors, which included the geographic location, exposure to violent forms of discipline, and positive caregiver-child relationships. These results demonstrate that a hybrid model combined with SHAP explainability can be helpful to identify complex and domain-specific factors of early childhood development. SHAP subgroup analysis shows urban predictions rely on behavior/context, while rural predictions depend more on caregiving, resources, and nutrition. The approach provides a transparent, data-driven mechanism to facilitate evidence-based policymaking and targeted interventions in accordance with Sustainable Development Goal 4.2.
Pre-trained on 357K children across 44 countries, this encoder solves the cold-start problem: with only 50 samples it beats gradient boosting by 8–12%. Zero-shot to unseen countries still reaches AUC 0.84.
Transfer LearningChild DevelopmentGlobal HealthSDGs
Abstract
A large number of children experience preventable developmental delays each year, yet deployment of machine learning in new countries is stymied by a data bottleneck: reliable models require thousands of samples, while new programs begin with fewer than 100. We introduce the first pre-trained encoder for global child development, trained on 357,709 children across 44 countries using UNICEF survey data. With only 50 training samples, the pre-trained encoder achieves an average AUC of 0.65 (95% CI: 0.56–0.72), outperforming cold-start gradient boosting by 8–12% across regions. At N = 500, the encoder achieves AUC of 0.73. Zero-shot deployment to unseen countries achieves AUCs up to 0.84. We apply a transfer learning bound to explain why pre-training diversity enables few-shot generalization, establishing that pre-trained encoders can transform the feasibility of ML for SDG 4.2.1 monitoring in resource-constrained settings.